软件学院师生论文被服务计算领域CCF A类国际期刊TSC 2025录用
近日,南开大学软件学院智能运维实验室的研究论文成功被服务计算领域的CCF A类国际学术期刊——IEEE Transactions on Services Computing (TSC) 2025 录用。以下是这篇论文的简介:
论文标题:A Comprehensive Benchmark and Empirical Study of Trace Anomaly Detection
作者:孙永谦,邵敏依,聂晓辉*,杨凯雯,李兴达,郝博文,张圣林,裴昶华,何东标,李彦彪,裴丹
作者单位:南开大学、中国科学院计算机网络信息中心、清华大学
Part.1 摘要
随着现代互联网应用复杂度的提升和微服务架构的广泛应用,高效的调用链异常检测技术对于维护系统稳定性至关重要。尽管已有多种调用链异常检测算法被提出,但目前缺乏对这些方法的全面评估,使得研究人员在实际应用中难以选择最适合的算法。为此,本研究提出了TADBench——一个全面且可扩展的调用链异常检测基准。
TADBench整合了五个数据集与七种典型算法,实现了数据格式的标准化,并提供了数据标注。为确保可复现性与公平的比较,该研究提出了模块化评估框架,支持端到端的模型评估。此外,通过在不同特征的数据集上评估算法性能,本研究为实际运用中的算法选择提供了有效的指导,缩小了学术研究与工业部署之间的差距。
Part.2 背景与挑战
微服务架构因其可扩展性、灵活性和高效资源利用等优势,成为许多互联网应用的主流选择。然而,其分布式结构也给系统监控和管理带来了挑战。调用链异常检测技术作为维护服务质量和增强用户体验的重要工具,能够实时识别服务交互网络中的问题,有助于故障的快速定位与修复。
然而,当前研究面临三大挑战:
1.数据可用性问题:现有的调用链数据集的格式不一致,且缺少准确的标注;
2.缺乏标准化评估框架:数据预处理方法不一致、算法复现不准确等问题导致了难以实现系统性的评估;
3.不同应用场景下算法选择:缺乏针对不同场景的实证分析与推荐策略。
Part.3 核心方法与系统架构
TADBench的设计包括四个主要阶段:调用链数据收集、数据预处理、模型适配和模型评估。
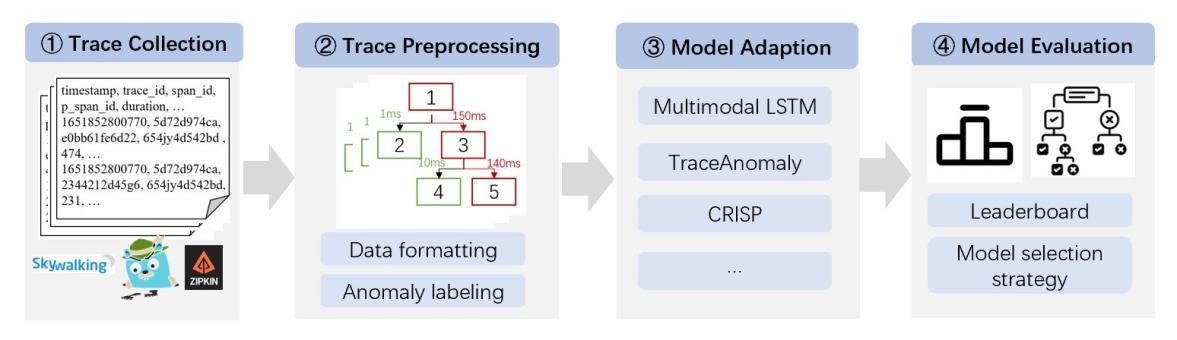
图1:TADBench的评估框架
首先,收集可用的调用链数据,并进行预处理。通过定义标准化数据格式,TADBench支持不同的数据集直接兼容任意算法。接着,基于高斯分布与Jaccard相似度,对数据进行延迟异常与结构异常两方面的数据标注,覆盖约21万条异常调用链。然后,设计算法SDK,保证算法格式的规范性和评估的一致性,并且支持快速集成新算法。最后,通过将不同的算法检测多个数据集,评估不同算法的性能。此外,为了更清晰、更全面地比较调用链异常检测算法,本研究设计并实现了一个算法排行榜。基于实验结果,本研究利用决策树提出了算法推荐策略。
Part.4 实验验证与部署成效
本研究在TrainTicket、GAIA、AIOps2020等五个数据集上对七个具有代表性的算法(Multimodal LSTM、TraceAnomaly、CRISP、PUTraceAD等)进行系统评估。此外,该研究还将这些数据按照不同的数据特征重新分类,以检测不同的算法在具有不同特征的数据上的具体表现。实验结果表明:
表1:不同算法的总体表现

l无通用最优算法:不同算法在不同数据集上表现各异,例如GTrace在TrainTicket上F1-score达99.4%,而TraceVAE在GAIA数据集上表现最优(90.9%)。
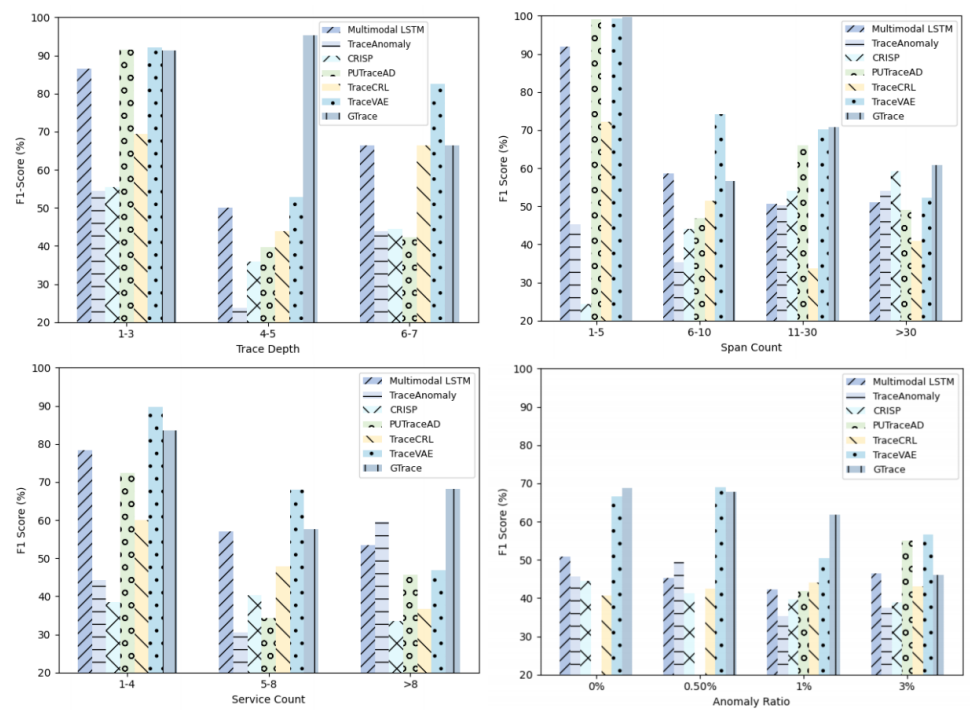
图2:不同算法在不同特征的数据上的表现
l数据特征影响性能:不同的算法在不同数据集上的表现受数据特征(如调用链深度、span数量、微服务数量和异常比例)的显著影响。
l效率对比:GTrace凭借缓存技术与分组策略实现最快检测速度,而TraceVAE因复杂编码结构训练耗时较长。
鉴于不同特征的数据集,最优算法的选择也不同,本研究基于决策树提出了一套算法推荐。例如,对于高异常比例的数据集,推荐使用PUTraceAD;对于包含大量span的调用链,GTrace是更好的选择。
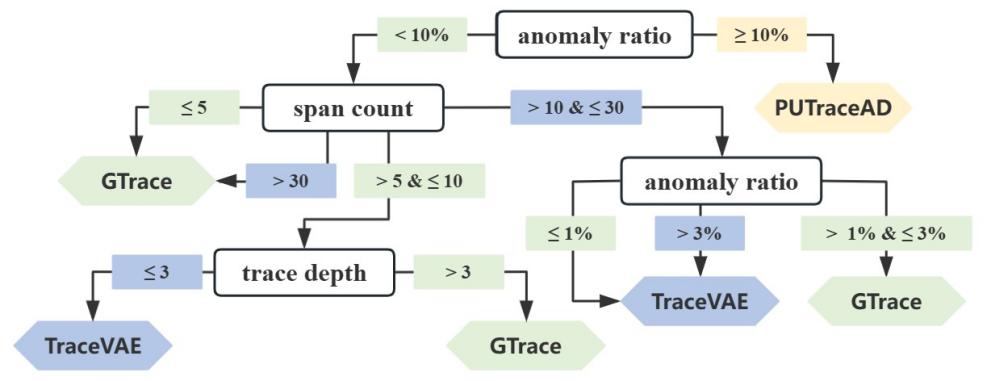
图3:基于不同数据特征的决策树
Part.5 研究意义与展望
TADBench作为首个调用链异常检测算法的全面实证研究,为调用链异常检测领域提供了端到端的评估框架和实用的算法选择指导。研究开源了包含104万条调用链、3.6GB的数据集与算法代码,推动领域可复现研究。通过标准化数据格式、整合数据集和算法,以及提出模块化评估框架,有效解决了现有研究中存在的问题。
展望未来,研究可进一步聚焦于细粒度的span级异常检测,并结合现有方法的优势进行优化。例如,集成TraceVAE的熵差缩减策略和GTrace的分组策略,以提升模型在复杂数据上的检测性能和检测效率。


 津南校区地址:天津市津南区海河教育园同砚路38号
津南校区地址:天津市津南区海河教育园同砚路38号
 邮编:300350
邮编:300350