深度学习模型已在众多实际应用中取得显著成果,尤其在自然语言处理(NLP)与信息检索(IR)任务中,如问答系统、主题分类、情感分析与产品评论等。在依赖大规模高质量标注数据进行训练的前提下,这些模型展现出良好的泛化能力。然而,标注成本高昂且过程复杂,同时,现实应用中不断涌现的新知识也对模型泛化能力提出了更高要求。为应对上述挑战,小样本学习(Few-Shot Learning, FSL)提出通过极少量标注样本快速适应新任务。在训练数据有限的情况下,构建一个信息丰富且具有代表性的小样本训练集成为关键问题。冷启动小样本数据选择(Cold-Start Few-Shot Data Selection)旨在从未标注数据池中选取少量多样且具代表性的样本,以提升模型在低资源场景下的泛化能力。然而,现有方法面临两大核心挑战:其一,数据池中的类别不平衡问题往往延续至所选子集中,易导致模型偏移与泛化能力下降;其二,多数方法仅考虑样本间的特征差异或模型不确定性,忽视了样本在语义簇中的整体代表性。
为此,论文《HCDS: Hierarchical Clustering for Cold-Start Few-Shot Data Selection》提出了一种面向冷启动场景的层次聚类样本选择方法,在无标注条件下有效选取信息丰富、语义代表性强的训练样本,为小样本学习与数据选择研究提供了新的解决思路。HCDS 首先通过类别级聚类结合伪标签生成与对比聚类学习,提取具有类别区分性的特征,缓解类别不平衡问题。随后,在每个类别簇内部执行表示级聚类,进行更细粒度的语义特征建模。最终,基于全局相似性策略从表示簇中选取代表性样本,实现差异性与代表性的综合考量。该方法在六个涵盖平衡与不平衡场景的公开数据集上开展系统实证研究,在 fine-tuning 与 prompt-tuning 两种语言模型训练范式下均显著优于现有先进方法,特别是在不平衡数据条件下表现尤为突出。此外,HCDS 在分布测试中展现出良好的泛化能力,并可兼容大型语言模型的上下文学习机制,具备广泛的应用前景。
该研究成果近期发表于CCF A 类会议 SIGIR 2025(International Conference onResearch and Development in Information Retrieval)。论文题为《HCDS: Hierarchical Clustering for Cold-Start Few-Shot Data Selection》,由博士生赵玉华担任第一作者,胡梦婷老师担任通讯.作者。
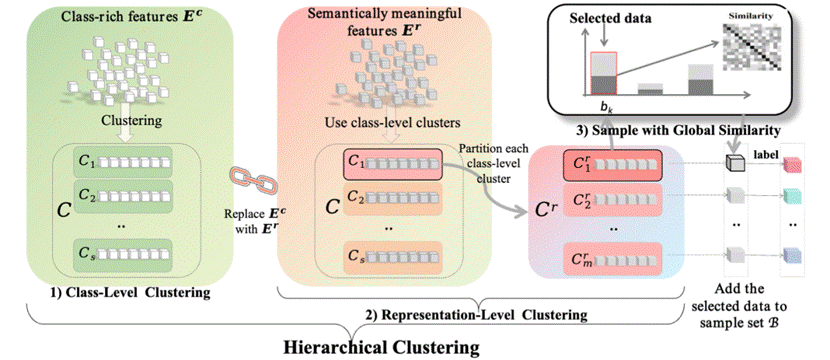
图1:HCDS框架图


 津南校区地址:天津市津南区海河教育园同砚路38号
津南校区地址:天津市津南区海河教育园同砚路38号
 邮编:300350
邮编:300350