SCELM框架采用“两阶段 + 三模块”架构:
离线阶段:构建历史变更知识库,统一结构化多模态数据,形成可供模型检索的向量历史经验;
在线阶段:实时捕获新变更信息,通过RAG技术从知识库中提取相似经验,结合当前数据利用大语言模型生成结构化诊断报告。
三大模块功能包括:
1、多模态数据统一表示与自然语言转化;
2、可查询的历史经验向量数据库构建;
3、基于RAG机制实现自动诊断报告生成,包括异常变更检测、故障变更诊断、变更根因定位、模型判断变更情况的原因依据以及给出解决方案等。
Part.4 实验验证与部署成效
论文在两个数据集上进行了深入实验:
D1:某电商公司实际生产数据,涵盖54个典型变更案例;
D2:基于开源Hipster Shop的微服务测试平台,涵盖364个可控实验样本。
对比SCWarn、Lumos、Kontrast等代表性方法,SCELM在准确率、召回率与F1值方面均显著领先,尤其在变更根因定位任务中,Top-1准确率可达87.9%。此外,框架具备较高的处理效率,平均每个变更案例仅需6秒左右即可完成三项任务。
在企业实际部署中,SCELM系统已连续运行11个月以上,累计辅助处理数万次变更操作,平均缩短90%以上的变更处理时长,得到了运维工程师的积极反馈。
Part.5 研究意义与展望
本研究表明,通过融合大语言模型与RAG技术,能够显著提升微服务系统在变更评估管理过程中的智能化与自动化水平,为后续相关研究提供了系统性方法论和可复用的实践路径。
未来,研究团队将探索结合RAG技术与小参数大语言模型微调策略,进一步提升模型在资源受限场景下的响应能力,同时考虑引入人机协同机制,增强模型输出的可解释性与可控性。
论文2:
论文标题:LLM-Augmented Ticket Aggregation for Low-cost Mobile OS Defect Resolution
作者:孙永谦, 郝博文, 王筱天, 赵晨宇, 赵咏欣, 石斌鹏, 张圣林, 葛俏, 李文虎, 魏华, 裴丹
作者单位:南开大学、华为、清华大学
Part.1 摘要
由于移动操作系统的复杂性及频繁更新,各类缺陷频繁出现,严重影响用户体验。为解决这一问题,厂商通常通过大规模Beta测试收集用户反馈工单。但海量的工单带来了巨大的处理挑战,特别是在工单派发(triage)阶段,工程师需快速、准确地将工单分配至合适团队。

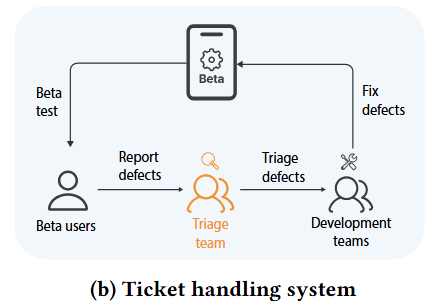
为此,研究团队提出了基于大语言模型的工单聚合框架——TixFusion。该框架通过无监督聚类聚合重复工单(duplicate tickets, 测试中产生的大量工单实际对应相同的系统缺陷),并结合LLM提取关键性区别信息(discriminative information),提升聚合精度。同时,TixFusion 可自动生成对聚合结果的解释文本,帮助工程师更好地理解聚合结果。
在鸿蒙操作系统的真实用户反馈工单数据集上进行评估表明,TixFusion在聚合效果方面优于现有方法,并已在实际场景中部署使用超过三个月,处理超20万条工单,将派单效率提升3.78倍。
Part.2 背景与挑战
移动操作系统缺陷不仅影响用户体验,甚至可能带来安全风险。为了解决这些问题,手机厂商通常会进行大规模的beta测试,并收集用户反馈的工单。然而,大量的工单给工单处理系统带来了巨大的挑战,尤其是在派单阶段,工程师需要将工单分配给相应的开发团队进行处理。现有的工单聚合方法需要大量的人工标记数据,导致成本高昂,难以推广至实际生产系统。
Part.3 核心方法与系统架构
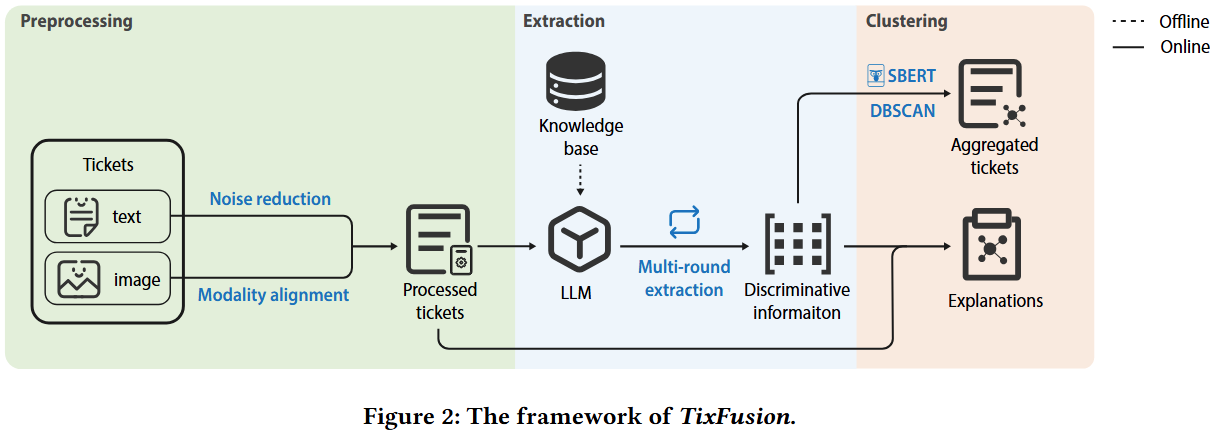
TixFusion 框架采用两阶段架构:
· 离线阶段: 利用少量标注数据进行上下文学习,构建知识库并微调大语言模型。
· 在线阶段: 对新工单进行预处理、提取区分性信息、无监督聚类,并生成聚合结果的解释。
TixFusion 框架的主要模块包括:
1. 预处理模块: 对工单进行降噪和模态对齐。
2. 提取模块: 利用 LLM 提取工单中的区分性信息。
3. 聚类模块: 利用无监督聚类算法对工单进行聚合。
4. 解释模块: 利用 LLM 自动生成对聚合结果的解释。
Part.4 实验验证与部署成效
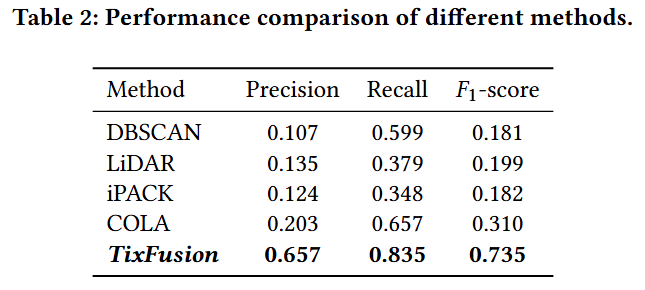
研究团队在来自鸿蒙系统的真实数据集上进行了实验,与DBSCAN、LiDAR、iPACK、COLA等方法对比,结果表明 TixFusion 的性能优于现有方法。
此外,TixFusion 已在华为鸿蒙系统中部署并运行了三个月,处理了超过 200,000 个工单,并将派单工程师的处理速度提高了 3.78 倍,显著缓解了工程师的工作压力。
Part.5 研究意义与展望
本研究展示了大语言模型与无监督聚类方法融合的强大潜力,不仅提高了工单处理效率,也大幅降低了对人工标注数据的依赖,并增强了解释能力。
未来,团队将探索LLM与传统机器学习方法的更深层次结合,以进一步提升聚合效果与系统鲁棒性。


 津南校区地址:天津市津南区海河教育园同砚路38号
津南校区地址:天津市津南区海河教育园同砚路38号
 邮编:300350
邮编:300350