软件学院师生论文被软件工程领域顶会ASE 2025录用
近日,南开大学软件学院智能计算实验室的论文《Fixing Broken Graphs: LLM-Powered Automatic Code Optimization for DNN Programs》被软件工程领域的CCF A类国际会议——IEEE/ACM International Conference on Automated Software Engineering (ASE) 2025录用。该会议于2025年11月16日至11月20日在韩国首尔举行。以下是论文简介:
论文标题: Fixing Broken Graphs: LLM-Powered Automatic Code Optimization for DNN Programs
作者: 王昊天*,隋轶丞*,谢宇东,刘一聪,孙羽菲,石昌青,张玉志
作者单位: 南开大学
摘要
深度学习编译器通过将用户代码捕获为计算图来优化程序执行。然而,开发者编写的程序往往包含复杂的Python语言特性,阻碍编译器识别完整计算图,导致次优性能。为此,本文提出GraphGlue,创新性地将解决计算图中断从复杂地编译器优化问题转换为用户代码修复问题。GraphGlue是一个利用大语言模型修复和优化DNN程序的多智能体系统。GraphGlue采用图断裂原因挖掘(GCM)识别断裂隐藏原因,并通过带拒绝采样的自校正机制(SRS)有效避免无效反馈尝试。
实验结果表明,GraphGlue相比TorchDynamo获得最高2.19倍加速,相比最先进编译器前端实现最高15.77倍内存节省,在1,411个真实程序上成功优化92.63%。
背景与挑战
随着模型复杂度增加,计算效率成为深度学习的关键瓶颈。主流框架引入计算图编译技术提升性能,但其效果严重依赖于捕获完整的计算图。由于深度学习模型 多层堆叠的特性,程序中一个不兼容操作也会导致计算图被分割成多个子图,严重影响优化效果。想要从源代码级别修改面临两大挑战:
(1)图断裂原因未暴露: TorchDynamo在追踪失败时默认生成子图并继续执行,输出的调试日志充斥编译器术语,难以定位问题。
(2)缺乏有效自校正: 传统反馈机制中,LLM一旦基于错误假设修复,后续尝试难以跳出错误路径。
研究方法与框架
图1为GraphGlue的总体流程,分为分析、修复、反馈三个阶段:
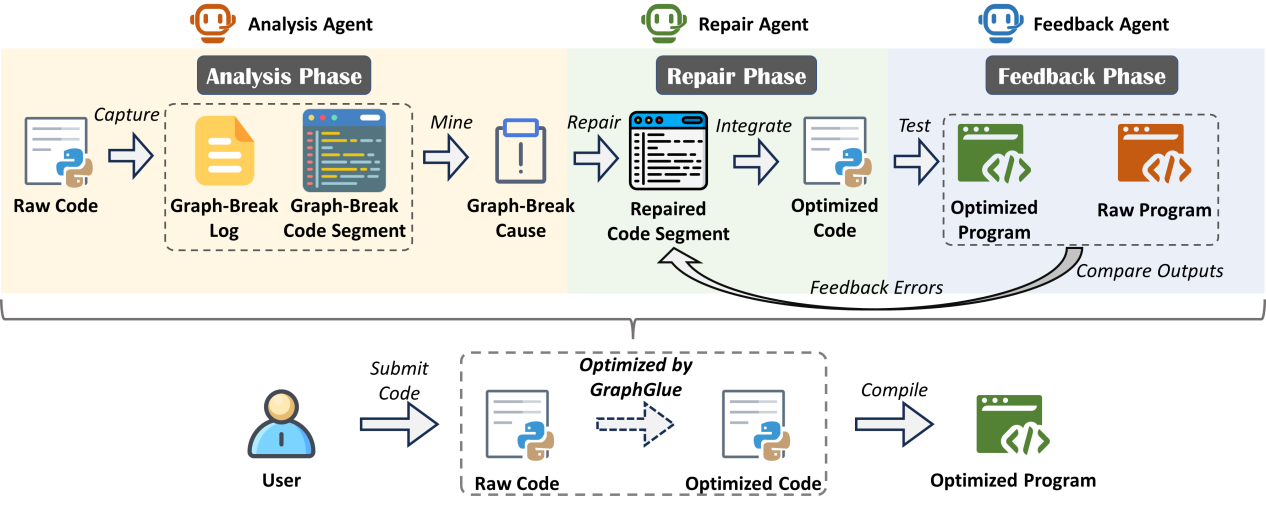
图1: GraphGlue整体流程
在分析阶段,Analysis Agent使用Dynamo编译器捕获图断裂点,通过图断裂原因挖掘(GCM)利用LLM将编译器日志转换为自然语言解释,并通过AST解析映射到源代码位置。
在修复阶段,Repair Agent整合静态分析和动态反馈,基于结构化提示生成代码修改,采用推理模型确保修复准确性。
在反馈阶段,Feedback Agent验证代码正确性和图完整性。带拒绝采样的自校正(SRS)机制在连续失败时丢弃错误轨迹重新开始,有效探索新的解决方案。
实验验证
为验证GraphGlue性能,研究团队在多个真实深度学习模型上进行全面实验,涵盖Transformer和CNN等多种架构。
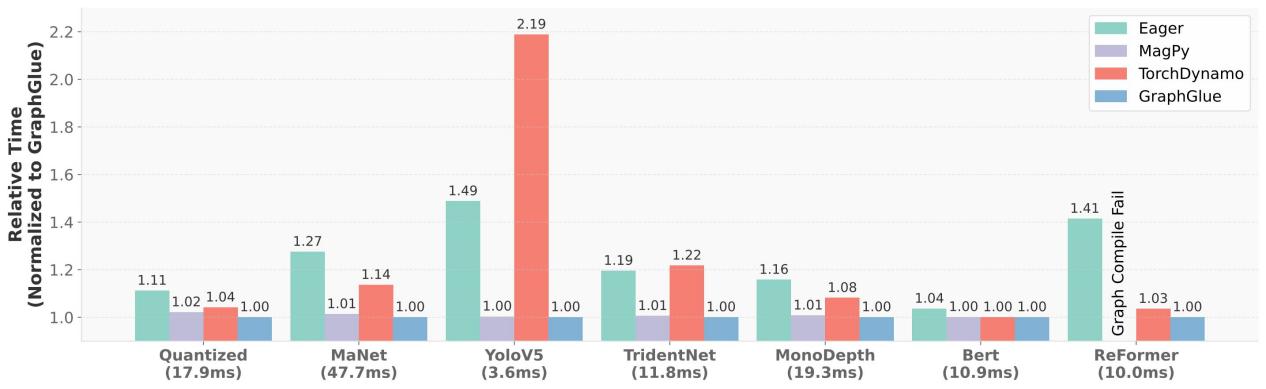
图2:端到端性能对比
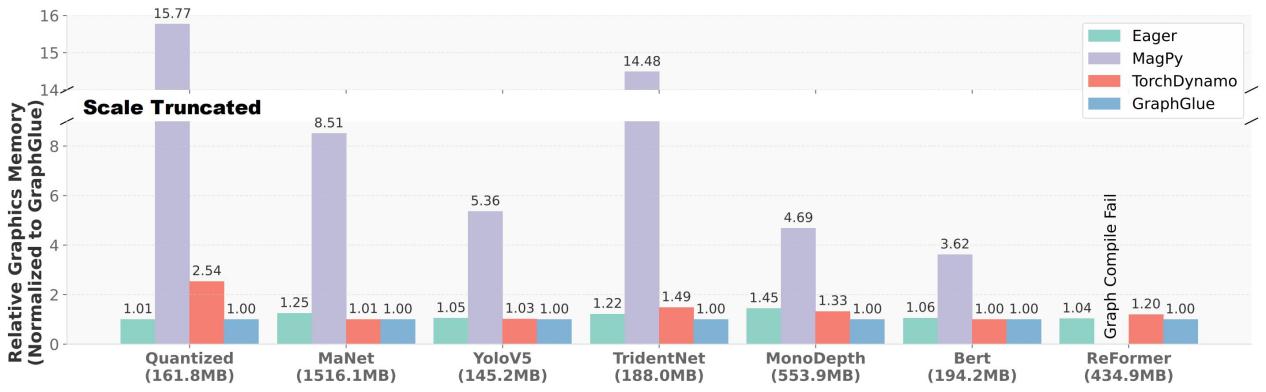
图3:端到端显存峰值对比
实验结果表明,GraphGlue相比TorchDynamo获得最高2.19倍加速(平均1.23倍),相比MagPy实现最高15.77倍(平均8.74倍)内存节省。
总结
GraphGlue为深度学习程序优化提供了创新思路,首次提出通过优化用户代码而非增强编译器功能来提升计算图捕获率,证明只需重写少量关键代码即可显著改善编译结果。
展望未来,GraphGlue将构建断裂-修复代码知识库以支持检索增强生成等新技术,并将优化支持扩展到训练场景和更多深度学习框架,进一步提升深度学习系统的性能与开发效率。


 津南校区地址:天津市津南区海河教育园同砚路38号
津南校区地址:天津市津南区海河教育园同砚路38号
 邮编:300350
邮编:300350