软件学院师生论文被软件工程领域顶会ICSE 2026录用
近日,南开大学软件学院智能运维实验室的论文《R-Log: Incentivizing Log Analysis Capability in LLMs via Reasoning-based Reinforcement Learning》被软件工程领域的CCF A类国际会议——International Conference on Software Engineering (ICSE 2026) 录用。该会议将于2026年4月12日至4月18日在巴西里约热内卢举行。以下是论文简介:
论文标题:R-Log: Incentivizing Log Analysis Capability in LLMs via Reasoning-based Reinforcement Learning
作者:刘逸伦,陈子昂,徐嵩,何名桂,陶仕敏,孟伟彬,谢于明,韩涛,赵春光,杜径舟,魏代猛,张圣林,孙永谦*
作者单位:南开大学、华为
Part.1 摘要
随着现代软件系统中日志数据的日益复杂,研究者开始借助大型语言模型(LLMs)实现自动化日志分析。现有方法通常依赖于基于日志-标签对的直接监督微调(Supervised Fine-Tuning, SFT)。然而,这种做法未能有效缓解通用LLM与专用日志数据之间的领域差异,从而限制了模型在真实日志场景下的泛化能力。此外,SFT的不平衡损失计算往往导致冗长的上下文稀释答案中关键且简洁的学习信号,从而引发幻觉问题。
为克服这些局限,我们提出了R-Log,这是一种新颖的基于推理的范式,模拟了人类工程师结构化、逐步分析的思维过程。该方法通过学习结论背后的潜在规则来提升模型的泛化能力。我们进一步在模拟的运维环境中采用强化学习(Reinforcement Learning, RL)对模型进行优化,通过直接奖励正确结果来减少幻觉。
R-Log首先在一个由2000余条推理轨迹组成的精心构建的数据集上进行冷启动,这些轨迹由13 条源自人工运维实践的策略指导,以建立初步的推理能力。随后,该能力通过带联合奖励函数的RL得到进一步提升。基于真实日志的实证评估表明,R-Log在五项日志分析任务上均优于现有方法,尤其在未见过的场景中提升达到228.05%。我们还设计了R-Log-fast,其速度提升 5 倍,同时保留了 93% 的效果。
Part.2背景与挑战
自动化日志分析在现代软件工程中至关重要,是保障系统可靠性、性能和安全性的基本手段。为了帮助运维工程师理解复杂系统中的多样化日志事件,日志分析领域研究了多种子任务。这些子任务涵盖从增强日志可解释性(日志解释)、日志解析,到将日志应用于实际问题求解,如异常检测,根因定位和解决方案推荐。
由于训练大量专用模型成本高且受限于历史日志不足,研究者开始探索利用单个大型语言模型(如 LogLM)处理多项日志分析任务,借助其强大的预训练能力提升通用性。然而,现有的基于SFT训练的大模型多日志任务分析方法存在一些局限性。
1.领域差异导致的分布偏移:LLM主要在自然语言语料上训练,而日志文本高度结构化(如 IP、状态码、路径等)。直接基于日志-标签进行监督微调(SFT)会加剧领域分布不匹配,难以学习日志分析所必需的内在规则,容易导致过拟合。
2.直接拟合答案(X→Y)的范式限制泛化能力:现有模型仅拟合输入(X)到答案(Y)的映射,而未学习人类工程师的推理步骤。面对未见过的日志模式或任务时,泛化性能大幅下降。
3.SFT 对复杂任务和长序列训练的不足:SFT 在逐词均匀分配损失,导致关键细节被冗长上下文淹没,引发幻觉。在包含推理步骤的训练中,冗长的推理部分产生比答案更多梯度信号,影响最终结论的准确性。同时随着任务上下文增大、场景多样化,SFT 在多任务和长输入序列上难以有效收敛。
Part.3核心方法与系统架构
R-Log的整体框架包括两个主要阶段:带有推理路径的日志数据构建和双阶段训练。

图1 R-Log的整体框架
在人类专家推理模板与数据构建部分,R-Log从运维手册、经验规则与工程师访谈中总结出 13 套推理模板,覆盖五类日志分析任务,并包含概念式与程序式两类思维方式。利用这些模板,将真实日志与答案扩展为约 2600 条带推理链的训练样本,使模型能够从结构化、类专家的推理步骤中学习有效分析模式
在双阶段训练架构部分,R-Log首先经过 SFT 冷启动对推理链与答案进行模仿学习,形成基础“先思考再回答”的输出行为,提高模型的指令遵循能力;随后在模拟的多日志任务运维场景中使用 GRPO 强化学习,通过设计联合奖励函数(结构正确性与任务相关准确度)进一步优化模型,使其在多任务环境中形成更可靠、更精准的分析策略。
Part.4实验验证与部署成效
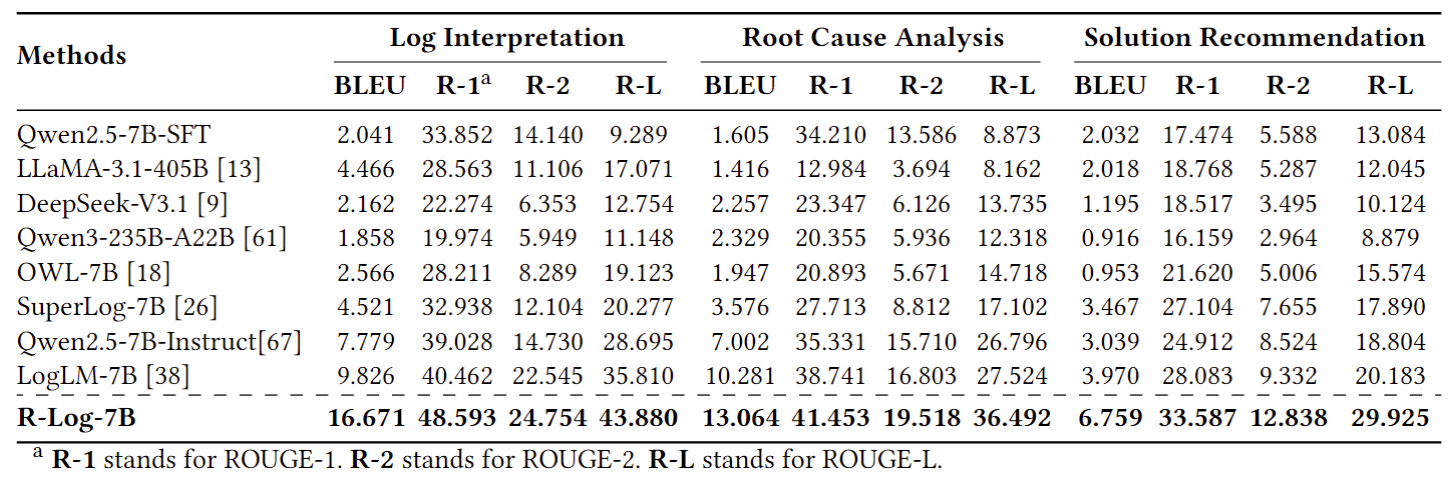
在五类日志分析任务(即日志解析、异常检测、日志解释、根因分析和解决方案推荐)方面,R-Log均显著超越现有最佳模型,包括 DeepSeek-V3.1、Qwen3-235B�、LLaMA3 系列以及专业日志模型 LogLM 和 SuperLog,体现出在结构化推理和跨任务理解上的显著优势。
表1 不同方法的日志解析性能
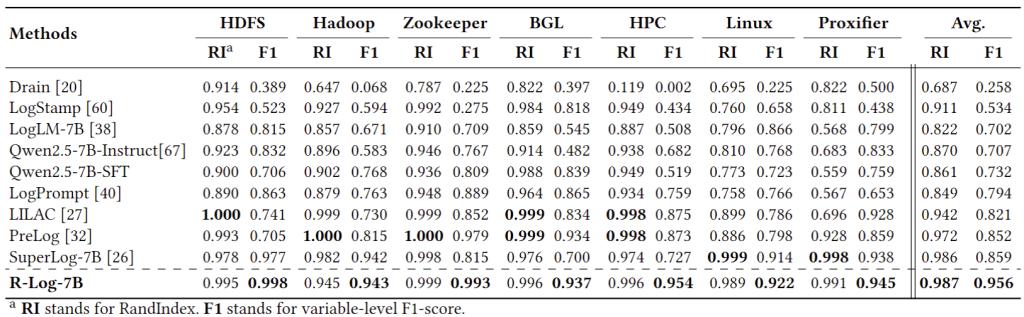
表2 不同方法的异常检测性能
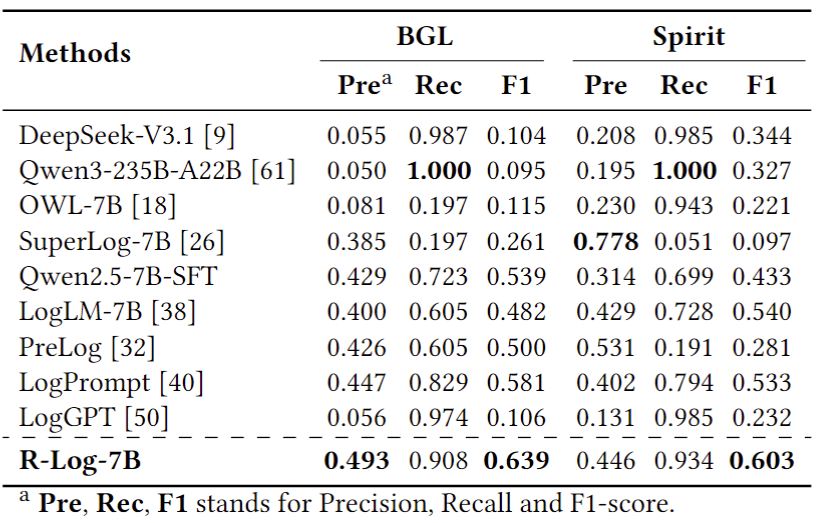
表3 不同方法的日志解释、根因定位和解决方案推荐性能
为验证 R-Log 在未见任务上的泛化能力,我们在日志变量分类任务上对其进行了无微调的零样本测试。结果表明,与仅经过 SFT 微调的模型相比,R-Log 能够更有效地利用已有模型知识来解决未见任务。
为解决推理链导致的推理耗时问题,R-Log设计了先输出答案再输出思考过程的反向结构,使推理时可在出现 <think> 后立即截断。该方法在保留 93% 性能的同时获得 5 倍速度提升,实现企业级高效部署,并已在华为内部应用。
Part.5研究意义与展望
R-Log 将日志分析从“标签拟合”提升到“显式推理”,使模型不仅给答案,还可以展示类似专业运维工程师的分析过程,显著提升可解释性与对未见日志任务的泛化能力。通过模板化推理学习与 RL 优化,单一模型即可同时执行解析、检测、解释、根因定位和解决方案生成。
后续可扩展更大规模推理数据、加入推理质量奖励、实现在线自适应学习,并进一步探索在复杂系统因果链分析、变更管理与实时日志决策中的应用,同时继续优化推理效率,以促进更多工业级落地。


 津南校区地址:天津市津南区海河教育园同砚路38号
津南校区地址:天津市津南区海河教育园同砚路38号
 邮编:300350
邮编:300350